

Spiegazioni semplici per materia complessa
- Quanto bisogna essere esperti di matematica e programmazione per studiare il machine learning
- Che cos’è il machine learning
- Che cos’è il deep learning
- Che cosa sono i dati
- Che cos’è l’apprendimento per rinforzo
1. Quanto bisogna essere esperti di matematica e programmazione per studiare il machine learning
Lo studio del machine learning richiede solo immaginazione, creatività e una mente visiva. Il machine learning si occupa dell’individuazione di modelli che emergono dal mondo e dell’utilizzo di tali modelli per fare previsioni sul futuro. Se piace trovare modelli e individuare correlazioni, allora si può utilizzare il machine learning. Se dicessi che ho smesso di fumare e che sto mangiando più verdure e facendo più attività fisica, che cosa si potrà predire riguardo la mia salute, tra un anno? Che forse migliorerà. Se dicessi che sono passato dall’indossare maglioni rossi a maglioni verdi, cosa si potrà predire riguardo la mia salute, tra un anno? Che forse non cambierà molto (potrebbe, ma non in base alle informazioni che ho dato).
Individuare queste correlazioni e questi modelli è ciò di cui si occupa il machine learning. L’unica differenza è che nel machine learning impieghiamo formule e numeri per definire questi schemi, per fare in modo che i computer li possano elaborare.
Per eseguire il machine learning sono necessarie alcune conoscenze di matematica e programmazione, ma non è necessario essere esperti. I già esperti in uno di questi campi, o in entrambi, troveranno sicuramente che le proprie competenze saranno premiate. Chi non lo sia potrà comunque imparare a usare il machine learning e apprendere i concetti matematici e di programmazione man mano che procede.
Leggi anche: Machine Learning con Python – intervista a Sebastian Raschka
Quanto al programmare, la quantità di codice di machine learning che scriveremo dipende da noi. I lavori nel campo del machine learning spaziano da chi passa tutto il giorno a programmare a chi non programma affatto. Molti pacchetti, API e strumenti ci aiutano a eseguire il machine learning con una minima attività di programmazione. Ogni giorno, il machine learning diventa sempre più disponibile per tutti nel mondo.
2. Che cos’è il machine learning
Per definire il machine learning, definiamo innanzitutto un termine più generale: l’intelligenza artificiale.
Che cos’è l’intelligenza artificiale
L’intelligenza artificiale (IA) è un termine generale, che definiamo come segue.
Intelligenza artificiale: l’insieme di tutti i compiti in cui un computer può prendere decisioni.
In molti casi, un computer prende queste decisioni imitando il modo in cui un essere umano prende le decisioni. In altri casi, possono imitare processi evolutivi, processi genetici o processi fisici. Ma in generale, ogni volta che vediamo un computer risolvere un problema da solo, che si tratti di guidare un’auto, trovare un percorso tra due punti, diagnosticare un paziente o consigliare un film, stiamo guardando l’intelligenza artificiale.
Che cos’è quindi il machine learning
Il machine learning è simile all’intelligenza artificiale e spesso le loro definizioni sono confuse. Il machine learning (ML) è una parte dell’intelligenza artificiale e lo definiamo come segue.
Machine learning: l’insieme di tutte le attività in cui un computer può prendere decisioni sulla base di dati.
Che cosa significa questo? Lo illustriamo con il diagramma nella figura qui sotto.

Il machine learning è una parte dell’intelligenza artificiale.
Torniamo a osservare in che modo gli esseri umani prendono le decisioni. In termini generali, prendiamo decisioni nei due modi seguenti:
- utilizzando la logica e il ragionamento;
- utilizzando la nostra esperienza.
Per esempio, immaginiamo di dover decidere quale auto acquistare. Possiamo osservare attentamente le caratteristiche dell’auto, come il prezzo, il consumo di carburante e la spaziosità, e cercare di trovare la combinazione più adatta al nostro budget. Questo significa usare la logica e il ragionamento. Se invece chiediamo a tutti i nostri amici quali auto possiedono, che cosa apprezzano o non apprezzano del loro mezzo, poi creiamo un elenco di informazioni e lo utilizziamo per decidere, allora stiamo usando l’esperienza (in questo caso, le esperienze dei nostri amici).
Il machine learning rappresenta il secondo metodo: prendere decisioni utilizzando la nostra esperienza. Nel mondo dei computer, il termine usato per parlare di esperienza è dati. Pertanto, nel machine learning, i computer prendono decisioni sulla base di dati. E così, ogni volta che utilizziamo un computer per risolvere un problema o per prendere una decisione utilizzando solo dati, stiamo utilizzando il machine learning. Colloquialmente, potremmo descrivere il machine learning nel modo seguente: il machine learning applica il buon senso, e ad applicarlo è un computer.
Il fatto di passare dalla risoluzione dei problemi utilizzando qualsiasi mezzo necessario al fare la stessa cosa utilizzando solo dati può sembrare un piccolo passo per un computer, ma è stato un passo enorme per l’umanità.

Il machine learning comprende tutte le attività in cui i computer prendono decisioni sulla base di dati. Allo stesso modo in cui gli esseri umani prendono decisioni basate su esperienze precedenti, i computer possono prendere decisioni basate su dati precedenti.
Un tempo, se volevamo far eseguire un compito a un computer, dovevamo scrivere un programma, vale a dire un intero insieme di istruzioni che il computer avrebbe dovuto seguire. Questo processo è utile per compiti semplici, ma alcuni compiti sono troppo complicati per questo schema di comportamento. Consideriamo per esempio il compito di identificare se un’immagine contiene una mela. Se iniziassimo a scrivere un programma per sviluppare questo compito, scopriremmo subito che è difficile.

Attraverso spiegazioni chiare, diagrammi, esempi ed esercizi, questa guida illustrata aiuta a capire come funzionano il machine learning e le AI senza dover faticare su migliaia di pagine di teoria.
Facciamo un passo indietro e poniamoci la seguente domanda. Come abbiamo imparato, come esseri umani, che aspetto ha una mela? Il modo in cui abbiamo imparato la maggior parte delle parole non è stato grazie a qualcuno che ci ha spiegato il loro significato; le abbiamo imparate ripetendole. Abbiamo visto molti oggetti nel corso della nostra infanzia, e gli adulti ci hanno detto qual era il loro nome. Per sapere che cosa fosse una mela, abbiamo visto molte mele nel corso degli anni, e intanto sentivamo la parola mela, finché un giorno abbiamo capito che cos’era una mela. Nel machine learning, questo è ciò che facciamo fare al computer. Mostriamo al computer tante immagini e gli diciamo quali contengono una mela (che costituisce i dati). Ripetiamo questo processo finché il computer non rileva i modelli e gli attributi corretti che costituiscono una mela. Alla fine del processo, quando diamo al computer una nuova immagine, può utilizzare questi modelli per determinare se l’immagine contiene una mela. Naturalmente, dobbiamo ancora programmare il computer in modo che rilevi questo schema. Per farlo abbiamo a disposizione diverse tecniche.
3. Che cos’è il deep learning
Così come il machine learning fa parte dell’intelligenza artificiale, il deep learning fa parte del machine learning. Nel paragrafo precedente, abbiamo scoperto che utilizziamo varie tecniche per fare in modo che il computer impari dai dati. Una di queste tecniche ha funzionato straordinariamente bene, quindi ha un proprio campo di studio, chiamato deep learning (DL), che definiamo come segue e come vediamo nella figura che segue.
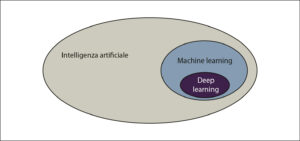
Il deep learning è una parte del machine learning.
Deep learning: il campo del machine learning che utilizza determinati oggetti chiamati reti neurali.
Che cosa sono le reti neurali? Il deep learning è probabilmente il tipo di machine learning più utilizzato, perché funziona davvero bene. Se stiamo usando una qualsiasi applicazione all’avanguardia, che esegue il riconoscimento di immagini, che genera testo, che gioca a Go o se conduciamo un’auto a guida autonoma, molto probabilmente stiamo usando il deep learning, in un modo o nell’altro.
In altre parole, il deep learning fa parte del machine learning, che a sua volta fa parte dell’intelligenza artificiale. Se parlassimo di trasporti, l’intelligenza artificiale sarebbe costituita dai veicoli, il machine learning dalle automobili e il deep learning dalle Ferrari.
4. Che cosa sono i dati
I dati sono semplicemente informazioni. Ogni volta che abbiamo una tabella di informazioni, abbiamo dei dati. Normalmente, ogni riga della nostra tabella è un punto di dati. Supponiamo, per esempio, di avere un dataset di animali domestici. In questo caso, ogni riga rappresenta un determinato animale domestico. Ogni animale domestico della tabella è descritto da alcune caratteristiche specifiche di quell’animale domestico.
Che cosa sono le caratteristiche?
Se i dati sono contenuti in una tabella, le caratteristiche sono le colonne della tabella. Nel nostro esempio degli animali domestici, le caratteristiche possono essere la taglia, il nome, il tipo o il peso. Le caratteristiche potrebbero anche essere i colori dei pixel in un’immagine dell’animale domestico. Questo è ciò che descrive i dati. Alcune caratteristiche, tuttavia, sono speciali e le chiamiamo etichette.
Etichette
Questo concetto è un po’ meno semplice, perché dipende dal contesto del problema che stiamo cercando di risolvere. Normalmente, se stiamo cercando di prevedere una particolare caratteristica basandoci sulle altre, quella caratteristica è l’etichetta. Se stiamo cercando di prevedere il tipo di animale domestico (per esempio, gatto o cane) in base alle informazioni disponibili su quell’animale, allora l’etichetta sarà il tipo di animale domestico (gatto/cane). Se stiamo cercando di prevedere se l’animale è malato o sano in base ai sintomi e ad altre informazioni, allora l’etichetta sarà lo stato dell’animale (malato/sano). Se stiamo cercando di prevedere l’età dell’animale, l’etichetta sarà l’età (un numero).
Previsioni
L’obiettivo di un modello predittivo di machine learning è indovinare le etichette nei dati. L’ipotesi fatta dal modello è chiamata previsione.
Ora che sappiamo che cosa sono le etichette, possiamo capire che esistono due tipi principali di dati: dati etichettati e dati non etichettati.
Dati etichettati e non etichettati
I dati etichettati sono dotati di etichette. I dati non etichettati sono privi di etichette. Un esempio di dati etichettati è un dataset di messaggi di posta elettronica con una colonna che specifica se i messaggi sono di spam o ham o con una colonna che specifica se i messaggi sono di lavoro. Un esempio di dati non etichettati è un dataset di e-mail che non ha una colonna che invece siamo interessati a prevedere.
Nella prossima figura vediamo tre dataset contenenti immagini di animali domestici. Il primo dataset ha una colonna che specifica il tipo di animale domestico, mentre il secondo dataset ha una colonna che specifica il peso dell’animale. Questi due sono esempi di dati etichettati. Il terzo dataset è costituito solo da immagini, non etichettate, pertanto si tratta di dati non etichettati.

I dati etichettati sono dotati di un’etichetta che può essere un tipo o un numero. I dati non etichettati sono forniti senza etichetta. Il dataset a sinistra è etichettato e l’etichetta indica il tipo di animale domestico (cane/gatto). Anche il dataset al centro è etichettato e l’etichetta riporta il peso dell’animale (in kg). Il dataset a destra non è etichettato.
Naturalmente questa definizione contiene qualche ambiguità, perché, a seconda del problema, decidiamo se una particolare caratteristica si qualifica come etichetta. Pertanto, molte volte, per determinare se i dati sono etichettati o non etichettati, occorre valutare il problema che stiamo cercando di risolvere.
5. Che cos’è l’apprendimento per rinforzo
L’apprendimento per rinforzo è un altro tipo di machine learning in cui non vengono forniti dati e dobbiamo fare in modo che il computer esegua un compito. Invece dei dati, il modello riceve un ambiente e un agente che è incaricato di esplorare questo ambiente. L’agente ha un obiettivo o una serie di obiettivi. L’ambiente prevede ricompense e punizioni, che guidano l’agente a prendere le decisioni giuste per raggiungere il suo obiettivo. Tutto ciò suona un po’ astratto, ma vediamo un esempio.
Esempio: un mondo a griglia
In questa figura vediamo un mondo a griglia con un robot nell’angolo in basso a sinistra. Quello è il nostro agente. Il suo obiettivo è raggiungere lo scrigno del tesoro in alto a destra. Nella griglia possiamo vedere anche una montagna, il che significa che non possiamo attraversare quel quadrato, perché il robot non può scalare le montagne. Vediamo anche un drago che attaccherà il robot se quest’ultimo oserà portarsi nella sua casella, il che significa che parte del nostro obiettivo è non finire laggiù.

Un mondo a griglia in cui il nostro agente è un robot. L’obiettivo del robot è trovare lo scrigno del tesoro, evitando il drago. La montagna rappresenta un luogo attraverso il quale il robot non può passare.
Questo è il gioco, e per dare al robot informazioni su come procedere, manteniamo un punteggio. Il punteggio parte da zero. Se il robot arriva allo scrigno del tesoro, guadagna 100 punti. Se il robot raggiunge il drago, perde 50 punti. E per essere sicuri che il nostro robot si muova velocemente, possiamo dire che per ogni passo che fa, perde 1 punto, perché il robot consuma energia mentre cammina.
Il modo per addestrare questo algoritmo, in termini molto approssimativi, è il seguente: il robot inizia a camminare, registrando il suo punteggio e ricordando quali passi lo hanno portato lì. A un certo punto, potrebbe incontrare il drago, perdendo molti punti. Quindi impara ad associare il quadrato del drago e i quadrati vicini a punteggi bassi. A un certo punto potrebbe anche finire sullo scrigno del tesoro e imparare ad associare quel quadrato e quelli vicini ai punteggi più alti. Dopo aver giocato a lungo a questo gioco, il robot si sarà fatto una buona idea del valore di ogni quadrato e potrà intraprendere il percorso seguendo i quadrati fino allo scrigno del tesoro. La figura sottostante mostra un possibile percorso, anche se non è l’ideale, perché passa troppo vicino al drago. Riusciamo a pensarne uno migliore?

Ecco un percorso che il robot potrebbe intraprendere per trovare lo scrigno del tesoro. Ce n’è uno migliore?
L’apprendimento per rinforzo ha numerose applicazioni all’avanguardia, tra cui le seguenti.
- Giochi: i recenti progressi nell’insegnare ai computer a vincere nei giochi, come il Go o gli scacchi, utilizzano l’apprendimento per rinforzo. Inoltre, agli agenti è stato insegnato a vincere in giochi Atari come Breakout o Super Mario.
- Robotica: l’apprendimento per rinforzo è ampiamente utilizzato per aiutare i robot a svolgere compiti come raccogliere scatole, pulire una stanza e persino danzare.
- Auto a guida autonoma: le tecniche di apprendimento per rinforzo vengono utilizzate per aiutare l’auto a svolgere molti compiti come la pianificazione del percorso o il comportamento in ambienti particolari.
Questo articolo richiama contenuti da Machine Learning spiegato in modo facile, di Luis G. Serrano.
Immagine di apertura originale di Andy Kelly su Unsplash.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Libri che potrebbero interessarti
